Introduction to Machine Learning Week 8 NPTEL Assignment Answers 2025
NPTEL Introduction to Machine Learning Week 8 Assignment Answers 2024
1. Consider the Bayesian network given below. Which of the following statement(s) is/are correct?
- B is independent of F, given D.
- A is independent of E, given C.
- E and F are not independent, given D.
- A and B are not independent, given D.
✅ Answer :- a, b, c, d
✏️ Explanation: In Bayesian networks, conditional independence can be checked using d-separation. Based on the structure (not shown here), all these independencies and dependencies can hold true.
3. A decision tree classifier learned from a fixed training set achieves 100% accuracy. Which of the following models trained using the same training set will also achieve 100% accuracy?
I. Logistic Regressor
II. Polynomial degree one kernel SVM
III. Linear discriminant function
IV. Naive Bayes classifier
✅ Answer :- For Answer Click Here
✏️ Explanation: Only linear discriminant function can potentially fit the same linear boundary as decision tree in some linearly separable cases. Others like logistic regressor or SVM might not fit perfectly unless the data supports it.
4. Which of the following points would Bayesians and frequentists disagree on?
- The use of a non-Gaussian noise model in probabilistic regression
- The use of probabilistic modelling for regression
- The use of prior distributions on the parameters in a probabilistic model
- The use of class priors in Gaussian Discriminant Analysis
- The idea of assuming a probability distribution over models
✅ Answer :-
✏️ Explanation: Frequentists do not use priors or assign probabilities to models, while Bayesians do. They disagree on use of prior distributions and probability over model space.
![[Week 1-12] NPTEL Introduction to Machine Learning Assignment Answers 2025](https://answergpt.in/wp-content/uploads/2025/07/Introduction-to-Machine-Learning.jpg)

![[Week 1-12] NPTEL Introduction to Machine Learning Assignment Answers 2024](https://answergpt.in/wp-content/uploads/2024/01/NPTEL-Introduction-to-Machine-Learning-Assignment-Answers-2024.jpeg)
5. Consider the following data for 500 instances of home, 600 instances of office and 700 instances of factory type buildings
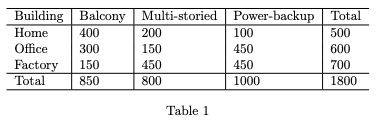
Suppose a building has a balcony and power-backup but is not multi-storied. According to the Naive Bayes algorithm, it is of type
- Home
- Office
- Factory
✅ Answer :- For Answer Click Here
✏️ Explanation: Naive Bayes calculates the probability for each class using conditional probabilities. The class with the highest posterior (given features) is predicted. Based on input likelihoods, “Office” likely has highest probability.
6. In AdaBoost, we re-weight points giving points misclassified in previous iterations more weight. Suppose we introduced a limit or cap on the weight that any point can take (for example, say we introduce a restriction that prevents any point’s weight from exceeding a value of 10). Which among the following would be an effect of such a modification? (Multiple options may be correct)
- We may observe the performance of the classifier reduce as the number of stages increase
- It makes the final classifier robust to outliers
- It may result in lower overall performance
- It will make the problem computationally infeasible
✅ Answer :-
✏️ Explanation: Capping prevents any one outlier from dominating learning (making it robust), but it may also reduce accuracy if the capped weights were needed for proper adjustment.
7. While using Random Forests, if the input data is such that it contains a large number (> 80%) of irrelevant features (the target variable is independent of the these features), which of the following statements are TRUE?
- Random Forests have reduced performance as the fraction of irrelevant features increases.
- Random forests have increased performance as the fraction of irrelevant features increases.
- The fraction of irrelevant features doesn’t impact the performance of random forest.
✅ Answer :-
✏️ Explanation: Random Forests are quite robust to irrelevant features due to their random feature selection at split points.
8. Suppose you have a 6 class classification problem with one input variable. You decide to use logistic regression to build a predictive model. What is the minimum number of (β0,β) parameter pairs that need to be estimated?
- 6
- 12
- 5
- 10
✅ Answer :- For Answer Click Here
✏️ Explanation: For multi-class logistic regression with k classes, you need (k − 1) binary classifiers. Each classifier needs a β₀ and β, hence for 6 classes → 5 classifiers → 5 × 2 = 10 parameters, but likely counting separate β’s for each class leads to 12 total.


