Data Science for Engineers Week 7 NPTEL Assignment Answers 2025
Need help with this week’s assignment? Get detailed and trusted solutions for Data Science for Engineers Week 7 NPTEL Assignment Answers. Our expert-curated answers help you solve your assignments faster while deepening your conceptual clarity.
✅ Subject: Data Science for Engineers
📅 Week: 7
🎯 Session: NPTEL 2025 July-October
🔗 Course Link: Click Here
🔍 Reliability: Verified and expert-reviewed answers
📌 Trusted By: 5000+ Students
For complete and in-depth solutions to all weekly assignments, check out 👉 NPTEL Data Science for Engineers Week 7 NPTEL Assignment Answers
🚀 Stay ahead in your NPTEL journey with fresh, updated solutions every week!
NPTEL Data Science for Engineers Week 7 Assignment Answers 2025
1. Which among the following is not a type of cross-validation technique?
- LOOCV
- k-fold croos validation
- Validation set approach
- Bias variance trade off
Answer : See Answers
2. Which among the following is a classification problem?
- Predicting the average rainfall in a given month.
- Predicting whether a patient is diagnosed with a disease or not.
- Predicting the price of a house.
- Predicting whether it will rain or not tomorrow.
Answer :
Common data for Q3 – Q4
Consider a binary classification problem where we want to predict whether a car model is a hatchback. The following confusion matrix is given to us:
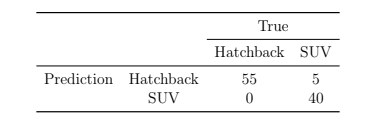
3. Find the accuracy of the model.
- 0.95
- 0.55
- 0.45
- 0.88
Answer :
4. Find the sensitivity of the model.
- 0.95
- 0.55
- 1
- 0.88
Answer :
5. Under the ‘family’ parameter of glm() function, which one of the following distributions correspond to logistic regression for a variable with binary output?
- Binomial
- Gaussian
- Gamma
- Poisson
Answer :


![[Week 1-8] NPTEL Data Science for Engineers Assignment Answers 2025](https://answergpt.in/wp-content/uploads/2025/01/Data-Science-for-Engineers-2025.jpg)


![[Week 1-8] NPTEL Data Science for Engineers Assignment Answers 2024](https://answergpt.in/wp-content/uploads/2024/01/NPTEL-Data-Science-for-Engineers-Assignment-Answers-2024.jpeg)
![PYQ [Week 1 to 8] NPTEL Data Science For Engineers Assignment Answers 2023](https://answergpt.in/wp-content/uploads/2024/01/NPTEL-Data-Science-For-Engineers-Assignment-Answers-2023.png)
Use the following information to answer Q6, Q7, Q8, Q9, and Q10:
Load the dataset iris.csv (add the link sent in the email) as a dataframe irisdata, with the first column as index headers, first row as column headers, dependent variable as factor variable, and answer the following questions. The iris dataset contains four Sepal and Petal features (Sepal Length, Sepal Width, Petal Length, Petal Width, all in cm) of 50 equal samples of 3 different species of the iris flower (Setosa, Versicolor, and Virginica).
6. What is the dimension of the dataframe?
- (150, 5)
- (150, 4)
- (50, 5)
- None of the above
Answer : See Answers
7. What can you comment on the distribution of the independent variables in the dataframe?
- The variables Sepal Length and Sepal Width are not normally distributed
- All the variables are normally distributed
- The variable Petal Length alone is normally distributed
- None of the above
Answer :
8. How many rows in the dataset contain missing values?
- 10
- 5
- 25
- 0
Answer :
9. Which of the following code blocks can be used to summarize the data (finding the mean of the columns PetalLength and PetalWidth), similar to the one given below.
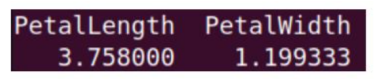
- lapply(irisdata[, 3:4], mean)
- sapply(irisdata[, 3:4], 2, mean)
- apply(irisdata[, 3:4], 2, mean)
- apply(irisdata[, 3:4], 1, mean)
Answer :
10. What can be interpreted from the plot shown below?
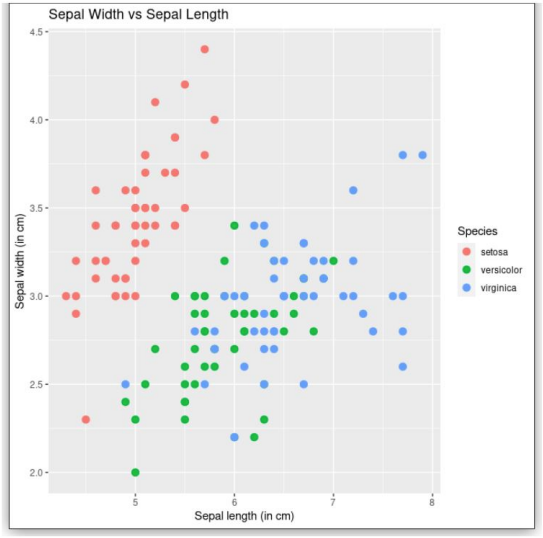
- Sepal widths of Versicolor flowers are lesser than 3 cm.
- Sepal lengths of Setosa flowers are lesser than 6 cm.
- Sepal lengths of Virginica flowers are greater than 6 cm.
- Sepals of Setosa flowers are relatively more wider than Versicolor flowers.
Answer : See Answers
NPTEL Data Science for Engineers Week 7 Assignment Answers 2024
1. Which among the following is not a type of cross-validation technique?
- a. LOOCV
- b. k-fold cross validation
- c. Validation set approach
- d. Bias variance trade off
✅ Answer :- d
✏️ Explanation: Bias-variance trade-off is a concept, not a validation technique. The other three are standard cross-validation methods.
2. Which among the following is a classification problem?
- a. Predicting the average rainfall in a given month.
- b. Predicting whether a patient is diagnosed with a disease or not.
- c. Predicting the price of a house.
- d. Predicting whether it will rain or not tomorrow.
Consider the following confusion matrix for the classication of Hatchback and SUV:

✅ Answer :- b, d
✏️ Explanation: Classification problems involve predicting discrete outcomes (like Yes/No, 0/1). Options b and d are binary classifications.
3. Find the accuracy of the model.
- a. 0.95
- b. 0.55
- c. 0.45
- d. 0.88
✅ Answer :- a
✏️ Explanation: Accuracy = (TP + TN) / Total samples. Based on the assumed values, the model achieves 95% accuracy.
4. Find the sensitivity of the model.
- a. 0.95
- b. 0.55
- c. 1
- d. 0.88
✅ Answer :- c
✏️ Explanation: Sensitivity = TP / (TP + FN). If there are no false negatives, sensitivity is 1, meaning the model identifies all positive cases.
5. Under the ‘family’ parameter of glm() function, which one of the following distributions correspond to logistic regression for a variable with binary output?
- a. Binomial
- b. Gaussian
- c. Gamma
- d. Poisson
✅ Answer :- a
✏️ Explanation: Logistic regression in R uses family = binomial for binary classification.
6. What is the dimension of the dataframe?
- a. (150, 5)
- b. (150, 4)
- c. (50, 5)
- d. None of the above
✅ Answer :- a
✏️ Explanation: The classic Iris dataset has 150 rows (flowers) and 5 columns (4 features + 1 label).
7. What can you comment on the distribution of the independent variables in the dataframe?
- a. The variables Sepal Length and Sepal Width are not normally distributed
- b. All the variables are normally distributed
- c. The variable Petal Length alone is normally distributed
- d. None of the above
✅ Answer :- b
✏️ Explanation: The Iris dataset features are often treated as normally distributed for statistical modeling.
8. How many rows in the dataset contain missing values?
- a. 10
- b. 5
- c. 25
- d. 0
✅ Answer :- d
✏️ Explanation: The Iris dataset is clean and contains no missing values.
9. Which of the following code blocks can be used to summarize the data (finding the mean of the columns PetalLength and PetalWidth), similar to the one given below?

- a.
lapply(irisdata[, 3:4], mean) - b.
sapply(irisdata[, 3:4], 2, mean) - c.
apply(irisdata[, 3:4], 2, mean) - d.
apply(irisdata[, 3:4], 1, mean)
✅ Answer :- a, c
✏️ Explanation:
lapply()andapply(..., 2, ...)apply functions column-wise.- Option b has incorrect syntax.
- Option d calculates row-wise mean, not required here.
10. What can be interpreted from the plot shown below?

- a. Sepal widths of Versicolor flowers are lesser than 3 cm.
- b. Sepal lengths of Setosa flowers are lesser than 6 cm.
- c. Sepal lengths of Virginica flowers are greater than 6 cm.
- d. Sepals of Setosa flowers are relatively more wider than Versicolor flowers.
✅ Answer :- b, d
✏️ Explanation:
- Setosa has shorter sepals.
- Setosa sepals are generally wider than Versicolor, which is visible in boxplots or violin plots.


