Introduction to Machine Learning Week 5 NPTEL Assignment Answers 2025
Need help with this week’s assignment? Get detailed and trusted solutions for Introduction to Machine Learning Week 5 NPTEL Assignment Answers. Our expert-curated answers help you solve your assignments faster while deepening your conceptual clarity.
✅ Subject: Introduction to Machine Learning (nptel ml Answers)
📅 Week: 5
🎯 Session: NPTEL 2025 July-October
🔗 Course Link: Click Here
🔍 Reliability: Verified and expert-reviewed answers
📌 Trusted By: 5000+ Students
For complete and in-depth solutions to all weekly assignments, check out 👉 NPTEL Introduction to Machine Learning Week 5 Assignment Answers
🚀 Stay ahead in your NPTEL journey with fresh, updated solutions every week!
NPTEL Introduction to Machine Learning Week 5 Assignment Answers 2025
1. Given a 3 layer neural network which takes in 10 inputs, has 5 hidden units and outputs 10 outputs, how many parameters are present in this network?
- 115
- 500
- 25
- 100
Answer : See Answers
2. Recall the XOR(tabulated below) example from class where we did a transformation of features to make it linearly separable. Which of the following transformations can also work?
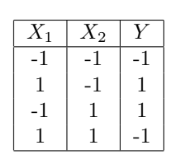
- Rotating x1 and x2 by a fixed angle.
- Adding a third dimension z=x∗y
- Adding a third dimension z=x2+y2
- None of the above
Answer :
3. We use several techniques to ensure the weights of the neural network are small (such as random initialization around 0 or regularisation). What conclusions can we draw if weights of our ANN are high?
- (a) Model has overfitted.
- (b) It was initialized incorrectly.
- At least one of (a) or (b).
- None of the above.
Answer :
4. In a basic neural network, which of the following is generally considered a good initialization strategy for the weights?
- Initialize all weights to zero
- Initialize all weights to a constant non-zero value (e.g., 0.5)
- Initialize weights randomly with small values close to zero
- Initialize weights with large random values (e.g., between -10 and 10)
Answer :
5. Which of the following is the primary reason for rescaling input features before passing them to a neural network?
- To increase the complexity of the model
- To ensure all input features contribute equally to the initial learning process
- To reduce the number of parameters in the network
- To eliminate the need for activation functions
Answer :


![[Week 1-12] NPTEL Introduction to Machine Learning Assignment Answers 2025](https://answergpt.in/wp-content/uploads/2025/07/Introduction-to-Machine-Learning.jpg)


![[Week 1-12] NPTEL Introduction To Machine Learning Assignment Answers 2022](https://answergpt.in/wp-content/uploads/2024/06/Introduction-To-Machine-Learning-2022.jpg)
![[Week 1-12] NPTEL Introduction to Machine Learning Assignment Answers 2024](https://answergpt.in/wp-content/uploads/2024/01/NPTEL-Introduction-to-Machine-Learning-Assignment-Answers-2024.jpeg)
6.

- P(θ|D) is the likelihood, P(D|θ) is the posterior, P(θ) is the prior, P(D) is the evidence
- P(θ|D) is the posterior, P(D|θ) is the likelihood, P(θ) is the prior, P(D) is the evidence
- P(θ|D) is the evidence, P(D|θ) is the likelihood, P(θ) is the posterior, P(D) is the prior
- P(θ|D) is the prior, P(D|θ) is the evidence, P(θ) is the likelihood, P(D) is the posterior
Answer : See Answers
7. Why do we often use log-likelihood maximization instead of directly maximizing the likelihood in statistical learning?
- Log-likelihood provides a different optimal solution than likelihood maximization
- Log-likelihood is always faster to compute than likelihood
- Log-likelihood turns products into sums, making computations easier and more numerically stable
- Log-likelihood allows us to avoid using probability altogether
Answer :
8. In machine learning, if you have an infinite amount of data, but your prior distribution is incorrect, will you still converge to the right solution?
- Yes, with infinite data, the influence of the prior becomes negligible, and you will converge to the true underlying solution.
- No, the incorrect prior will always affect the convergence, and you may not reach the true solution even with infinite data.
- It depends on the type of model used; some models may still converge to the right solution, while others might not.
- The convergence to the right solution is not influenced by the prior, as infinite data will always lead to the correct solution regardless of the prior.
Answer :
9. Statement: Threshold function cannot be used as activation function for hidden layers.
Reason: Threshold functions do not introduce non-linearity.
- Statement is true and reason is false.
- Statement is false and reason is true.
- Both are true and the reason explains the statement.
- Both are true and the reason does not explain the statement.
Answer :
10. Choose the correct statement (multiple may be correct):
- MLE is a special case of MAP when prior is a uniform distribution.
- MLE acts as regularisation for MAP.
- MLE is a special case of MAP when prior is a beta disrubution .
- MAP acts as regularisation for MLE.
Answer : See Answers
NPTEL Introduction to Machine Learning Week 5 Assignment Answers 2024
1. Consider a feedforward neural network that performs regression on a p
-dimensional input to produce a scalar output. It has m hidden layers and each of these layers has k hidden units. What is the total number of trainable parameters in the network? Ignore the bias terms.
- pk+mk2
- pk+mk2+k
- pk+(m−1)k2+k
- p2+(m−1)pk+k
- p2+(m−1)pk+k2
Answer :- c
2.

Answer :- b
3.

Answer :- b, d
4. Which of the following statement(s) about the initialization of neural network weights is/are true?
- Two different initializations of the same network could converge to different minima.
- For a given initialization, gradient descent will converge to the same minima irrespective of the learning rate.
- The weights should be initialized to a constant value.
- The initial values of the weights should be sampled from a probability distribution.
Answer :- a, d
7. Consider a Bernoulli distribution with with p=0.7 (true value of the parameter). We draw samples from this distribution and compute an MAP estimate of p by assuming a prior distribution over p. Which of the following statement(s) is/are true?
- If the prior is Beta(2,6), we will likely require fewer samples for converging to the true value than if the prior is Beta(6,2).
- If the prior is Beta(6,2), we will likely require fewer samples for converging to the true value than if the prior is Beta(2,6).
- With a prior of Beta(2,100), the estimate will never converge to the true value, regardless of the number of samples used.
- With a prior of U(0,0.5)(i.e. uniform distribution between 0 and 0.5), the estimate will never converge to the true value, regardless of the number of samples used.
Answer :- b, d
8. Which of the following statement(s) about parameter estimation techniques is/are true?
- To obtain a distribution over the predicted values for a new data point, we need to compute an integral over the parameter space.
- The MAP estimate of the parameter gives a point prediction for a new data point.
- The MLE of a parameter gives a distribution of predicted values for a new data point.
- We need a point estimate of the parameter to compute a distribution of the predicted values for a new data point.
Answer :- a, b


