1. Which of the following is/are unsupervised learning problem(s)?
- Grouping documents into different categories based on their topics
- Forecasting the hourly temperature in a city based on historical temperature patterns
- Identifying close-knit communities of people in a social network
- Training an autonomous agent to drive a vehicle
- Identifying different species of animals from images
Answer :- a, c
2. Which of the following statement(s) about Reinforcement Learning (RL) is/are true?
- While learning a policy, the goal is to maximize the long-term reward.
- During training, the agent is explicitly provided the most optimal action to be taken in each state.
- The state of the environment changes based on the action taken by the agent.
- RL is used for building agents to play chess.
- RL is used for predicting the prices of apartments from their features.
Answer :- a, c, d
3. Which of the following is/are classification tasks(s)?
- Predicting whether an email is spam or not spam
- Predicting the number of COVID cases over a given period
- Predicting the score of a cricket team
- Identifying the language of a text document
Answer :- a, d
4. Which of the following is/are regression task(s)?
- Predicting whether or not a customer will repay a loan based on their credit history
- Forecasting the amount of rainfall in a given place
- Identifying the types of crops from aerial images of farms
- Predicting the future price of a stock
Answer :- b, d
5. Consider the following dataset. Fit a linear regression model of the form y=β0+β1×1+β2×2 using the mean-squared error loss. Using this model, the predicted value of y at the point (x1,x2)=(0.5,−1.0)is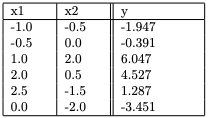
- −0.651
- −0.737
- 0.245−
- 0.872
Answer :- b
6. Consider the following dataset. Using a k-nearest neighbour (k-NN) regression model with k=3, predict the value of y at (x1,x2)=(0.5,−1.0) Use the Euclidean distance to find the nearest neighbours.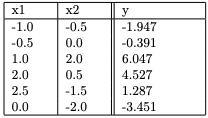
- −1.762
- −2.061
- −1.930
- −1.529
Answer :- c
7. Consider the following statements regarding linear regression and k-NN regression models. Select the true statements.
- A linear regressor requires the training data points during inference.
- A k-NN regressor requires the training data points during inference.
- A k-NN regressor with a higher value of k is less prone to overfitting.
- A linear regressor partitions the input space into multiple regions such that the prediction over a given region is constant.
Answer :- b, c
8. Consider a binary classification problem where we are given certain measurements from a blood test and need to predict whether the patient does not have a particular disease (class 0) or has the disease (class 1). In this problem, false negatives (incorrectly predicting that the patient is healthy) have more serious consequences as compared to false positives (incorrectly predicting that the patient has the disease). Which of the following is an appropriate cost matrix for this classification problem? The row denotes the true class and the column denotes the predicted class.

Answer :- c
9.
Consider the following dataset with three classes: 0, 1 and 2. x1 and x2 are the independent variables whereas y is the class label. Using a k-NN classifier with k = 3, predict the class label at the point (x1,x2)=(0.7,−0.8). Use the Euclidean distance to find the nearest neighbours.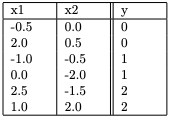
- 0
- 1
- 2
- Cannot be predicted
Answer :- b
10. Suppose that we train two kinds of regression models corresponding to the following equations.
- (i) y=β0+β1×1+β2×2
- (ii) y=β0+β1×1+β2×2+β3x1x2
Which of the following statement(s) is/are correct?
- On a given training dataset, the mean-squared error of (i) is always greater than or equal to that of (ii).
- (i) is likely to have a higher variance than (ii).
- (ii) is likely to have a higher variance than (i).
- If (ii) overfits the data, then (i) will definitely overfit.
- If (ii) underfits the data, then (i) will definitely underfit.
Answer :-a, c, d