Deep Learning for Computer Vision Week 4 NPTEL Assignment Answers 2025
Need help with this week’s assignment? Get detailed and trusted solutions for Deep Learning for Computer Vision Week 4 NPTEL Assignment Answers. Our expert-curated answers help you solve your assignments faster while deepening your conceptual clarity.
✅ Subject: Deep Learning for Computer Vision
📅 Week: 4
🎯 Session: NPTEL 2025 July-October
🔗 Course Link: Click Here
🔍 Reliability: Verified and expert-reviewed answers
📌 Trusted By: 5000+ Students
For complete and in-depth solutions to all weekly assignments, check out 👉 NPTEL Deep Learning for Computer Vision Week 4 NPTEL Assignment Answers
🚀 Stay ahead in your NPTEL journey with fresh, updated solutions every week!
NPTEL Deep Learning for Computer Vision Week 4 Assignment Answers 2025
1. Which one of the following statements is true:
- Weight change criterion is a method of ‘early stopping’ that checks whether or not the error is dropping over epochs to decide whether to continue training or stop.
- L2 norm tends to create more sparse weights than L1 norm.
- During training, Dropout randomly drops each neuron with probability p, and at test time you scale each neuron’s activation by the keep probability, 1−p.
- A single McCulloch-Pitts neuron is capable of modeling AND, OR, XOR, NOR, and NAND functions
Answer : See Answers
2. For a neural network f, let wij be the weight connecting neurons ai in hidden layer-1 to bj in adjacent hidden layer-2. Consider the following statements:

Choose the most appropriate answer:
- Statement-1 and Statement-2 are false
- Statement-1 and Statement-2 are true
- Statement-1 is true but Statement-2 is false
- Statement-1 is false but Statement-2 is true
Answer :
3. Which of the following statements are true? (Select all that apply)
- Sigmoid activation function σ(⋅) can be represented in terms of tanh activation function as below: σ(x)=(tanh(x/2)−1)/2
- The derivative of the sigmoid activation function is symmetric around the y-axis
- Gradient of a sigmoid neuron vanishes at saturation.
- Sigmoid activation is centered around 0 whereas tanh activation is centered around 0.5
Answer :
4.

Answer :



5. Consider the following statements P and Q regarding AlexNet and choose the correct option:
(P) In AlexNet, Response Normalization Layers were introduced to emulate the competitive nature of real neurons, where highly active neurons suppress the activity of neighboring neurons, creating
competition among different kernel outputs.
(Q) Convolutional layers contain only about 5% of the total parameters hence account for the least computation.
- Only statement P is true
- Only statement Q is true
- Both statements are true
- None of the statements is true
Answer :
6. Given an input image of shape (10,10,3), you want to use one of the two following layers:
- Fully connected layer with 2 neurons, with biases
- Convolutional layer with three 2×2 filters (with biases) with 0 padding and a stride of 2.
If you use the fully-connected layer, the input volume is “flattened” into a column vector before being fed into the layer. What is the difference in the number of trainable parameters between these two layers?
- The fully connected layer has 566 fewer parameters
- The convolutional layer has 518 fewer parameters
- The convolutional layer has 570 fewer parameters
- None of the above
Answer :
7. Which of the following statements is false?
- For a fixed padding, the bigger the size of the kernel, the smaller is the output after convolution.
- To get the output with the same size as that of the input, padding used is ⌊k2⌋ where k×k is the kernel used.
- The number of feature maps obtained after a convolution operation depends on the depth of the input but not on the number of filters.
- Stride is a hyper-parameter
Answer : See Answers
8. Compute the value for the following expression ELU(tanh(x)) where x=−1. 3 and α=0.3 (Round decimal point till 2 places).
Answer :
9. Using RMSProp-based Gradient Descent, find the new value of parameter θt+1, given that the old value θt=1.2, aggregated gradient Δθt=0.85, gradient accumulation rt−1=0.7, learning rate α=0.9, decay rate ρ=0.3 and small constant δ=10−7 (Round decimal point till 3 places).
Answer :
If we convolve a feature map of size 32 × 32 × 6 with a filter of size 7 × 7 × 3, with a stride of 1 across all dimensions and a padding of 0, the width of the output volume is ______A___________,the height of the output volume is ______B________ and the depth of the output volume is _________C___________
10. A _____
Answer :
11. B__________
Answer :
12. C______
Answer :
Assume that the feature map given below is generated from a convolution layer in CNN, after which a 2 × 2 Max Pooling layer with a stride 2 is applied to it.

While backpropagation, we get the following gradient for the pooling layer.
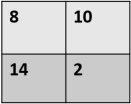
Assign the appropriate gradient value for the locations at feature map.
13. Location (1,1):-
Answer :
14. Location (1,4):
Answer :
15. Location (2,2):
Answer :
16. Location (3,1):
Answer :
17. Location (3,3):
Answer : See Answers
18. Location (4,3):
Answer :
For the same previous question, assign the appropriate gradient value for the locations at feature map but use Average Pooling layer instead of Max Pooling layer.
19. Location (1,1):
Answer :
20. Location (1,4):
Answer :
21. Location (2,2):
Answer :
22. Location (3,1):
Answer :
23. Location (3,3):
Answer :
24. Location (4,3):
Answer : See Answers


