Introduction to Machine Learning – IITKGP Week 5 NPTEL Assignment Answers 2025
Need help with this week’s assignment? Get detailed and trusted solutions for Introduction to Machine Learning – IITKGP Week 5 NPTEL Assignment Answers. Our expert-curated answers help you solve your assignments faster while deepening your conceptual clarity.
✅ Subject: Introduction to Machine Learning – IITKGP (nptel ml Answers)
📅 Week: 5
🎯 Session: NPTEL 2025 July-October
🔗 Course Link: Click Here
🔍 Reliability: Verified and expert-reviewed answers
📌 Trusted By: 5000+ Students
For complete and in-depth solutions to all weekly assignments, check out 👉 NPTEL Introduction to Machine Learning – IITKGP Week 5 Assignment Answers
🚀 Stay ahead in your NPTEL journey with fresh, updated solutions every week!
NPTEL Introduction to Machine Learning – IITKGP Week 5 Assignment Answers 2025
1.

Answer : See Answers
2. Which of the following option is true?
A) Linear regression error values have to normally distributed but not in the caseof the logistic regression
B) Logistic regression values have to be normally distributed but not in the case of the linear regression
C) Both linear and logistic regression error values have to be normally distributed
D) Both linear and logistic regression error values need not to be normally distributed
Answer :
3. Which of the following methods do we use to best fit the data in Logistic Regression?
A) Manhattan distance
B) Maximum Likelihood
C) Jaccard distance
D) Both A and B
Answer :
4.
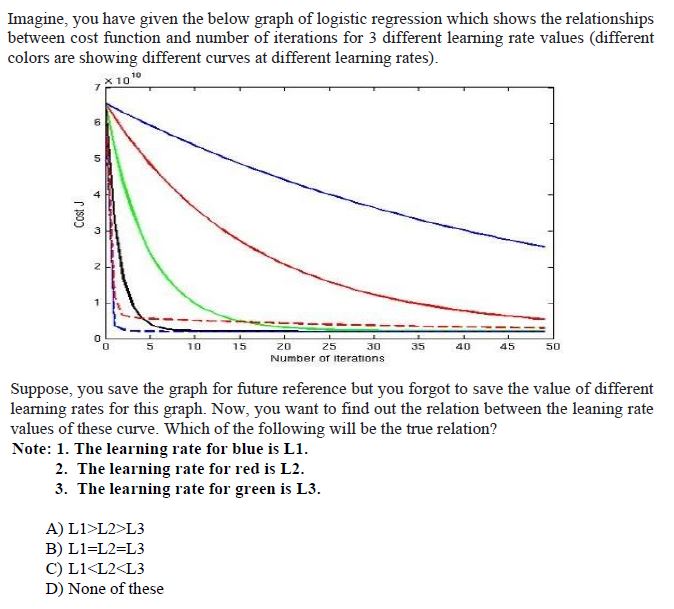
Answer :
5. State whether True or False.
After training an SVM, we can discard all examples which are not support vectors and can
still classify new examples.
A) TRUE
B) FALSE
Answer :





![PYQ [Week 1 to 8] NPTEL Introduction To Machine Learning – IITKGP Assignment Answers 2023](https://answergpt.in/wp-content/uploads/2024/01/NPTEL-Introduction-To-Machine-Learning-–-IITKGP-Assignment-Answers-2023.png)
6. Suppose you are dealing with 3 class classification problem and you want to train a SVM model on the data for that you are using One-vs-all method.
How many times we need to train our SVM model in such case?
A) 1
B) 2
C) 3
D) 4
Answer : See Answers
7. What is/are true about kernel in SVM?
- Kernel function map low dimensional data to high dimensional space
- It’s a similarity function
A) 1
B) 2
C) 1 and 2
D) None of these.
Answer :
8. Suppose you are using RBF kernel in SVM with high Gamma value. What does this signify?
A) The model would consider even far away points from hyperplane for modelling.
B) The model would consider only the points close to the hyperplane for modelling.
C) The model would not be affected by distance of points from hyperplane for modelling.
D) None of the above
Answer :
9.

Answer :
10. What do you conclude after seeing the visualization in previous question?
C1. The training error in first plot is higher as compared to the second and third plot.
C2. The best model for this regression problem is the last (third) plot because it has minimum training error (zero).
C3. Out of the 3 models, the second model is expected to perform best on unseen data.
C4. All will perform similarly because we have not seen the test data.
A) Cl and C2
B) C1 and C3
C) C2 and C3
D) C4
Answer : See Answers


