Introduction to Machine Learning Week 6 NPTEL Assignment Answers 2025
Need help with this week’s assignment? Get detailed and trusted solutions for Introduction to Machine Learning Week 6 NPTEL Assignment Answers. Our expert-curated answers help you solve your assignments faster while deepening your conceptual clarity.
✅ Subject: Introduction to Machine Learning (nptel ml Answers)
📅 Week: 6
🎯 Session: NPTEL 2025 July-October
🔗 Course Link: Click Here
🔍 Reliability: Verified and expert-reviewed answers
📌 Trusted By: 5000+ Students
For complete and in-depth solutions to all weekly assignments, check out 👉 NPTEL Introduction to Machine Learning Week 6 Assignment Answers
🚀 Stay ahead in your NPTEL journey with fresh, updated solutions every week!
NPTEL Introduction to Machine Learning Week 6 Assignment Answers 2025
1. Entropy for a 90-10 split between two classes is:
- 0.469
- 0.195
- 0.204
- None of the above
Answer : See Answers
2. Consider a dataset with only one attribute(categorical). Suppose, there are 8 unordered values in this attribute, how many possible combinations are needed to find the best split-point for building the decision tree classifier?
- 511
- 1023
- 512
- 127
Answer :
3. Having built a decision tree, we are using reduced error pruning to reduce the size of the tree. We select a node to collapse. For this particular node, on the left branch, there are three training data points with the following outputs: 5, 7, 9.6, and for the right branch, there are four training data points with the following outputs: 8.7, 9.8, 10.5, 11. The average value of the outputs of data points denotes the response of a branch. The original responses for data points along the two branches (left & right respectively) were response−left and, response−right and the new response after collapsing the node is response−new. What are the values for response−left, response−right and response−new (numbers in the option are given in the same order)?
- 9.6, 11, 10.4
- 7.2; 10; 8.8
- 5, 10.5, 15
- depends on the tree height.
Answer :
4. Which of the following is a good strategy for reducing the variance in a decision tree?
- If improvement of taking any split is very small, don’t make a split. (Early Stopping)
- Stop splitting a leaf when the number of points is less than a set threshold K.
- Stop splitting all leaves in the decision tree when any one leaf has less than a set threshold K points.
- None of the Above.
Answer :


![[Week 1-12] NPTEL Introduction to Machine Learning Assignment Answers 2025](https://answergpt.in/wp-content/uploads/2025/07/Introduction-to-Machine-Learning.jpg)


![[Week 1-12] NPTEL Introduction To Machine Learning Assignment Answers 2022](https://answergpt.in/wp-content/uploads/2024/06/Introduction-To-Machine-Learning-2022.jpg)
![[Week 1-12] NPTEL Introduction to Machine Learning Assignment Answers 2024](https://answergpt.in/wp-content/uploads/2024/01/NPTEL-Introduction-to-Machine-Learning-Assignment-Answers-2024.jpeg)
5. Which of the following statements about multiway splits in decision trees with categorical features is correct?
- They always result in deeper trees compared to binary splits
- They always provide better interpretability than binary splits
- They can lead to overfitting when dealing with high-cardinality categorical features
- They are computationally less expensive than binary splits for all categorical features
Answer :
6. Which of the following statements about imputation in data preprocessing is most accurate?
- Mean imputation is always the best method for handling missing numerical data
- Imputation should always be performed after splitting the data into training and test sets
- Missing data is best handled by simply removing all rows with any missing values
- Multiple imputation typically produces less biased estimates than single imputation methods
Answer :
7. Consider the following dataset:
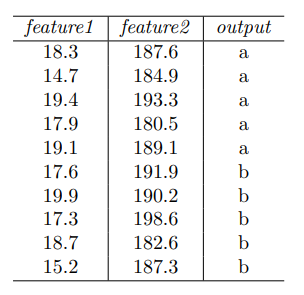
Which among the following split-points for feature2 would give the best split according to the misclassification error?
- 186.5
- 188.6
- 189.2
- 198.1
Answer : See Answers
NPTEL Introduction to Machine Learning Week 6 Assignment Answers 2024
1. From the given dataset, choose the optimal decision tree learned by a greedy approach:

✅ Answer :- c
✏️ Explanation: Greedy decision tree algorithms like ID3 or C4.5 choose splits based on the best immediate gain. Option C represents the most optimal such decision tree (based on highest information gain or Gini decrease per step).
2. Which of the following properties are characteristic of decision trees?
- High bias
- High variance
- Lack of smoothness of prediction surfaces
- Unbounded parameter set
✅ Answer :- b, c, d
✏️ Explanation: Decision trees typically have low bias but high variance. Their decision boundaries are piecewise constant (not smooth). They also don’t limit the number of parameters if the tree grows deep.
3. Entropy for a 50−50 split between two classes is:
(a) 0
(b) 0.5
(c) 1
(d) None of the above
✅ Answer :- For Answer Click Here
✏️ Explanation: Entropy = -p log₂(p) – q log₂(q). For p = q = 0.5, entropy = 1 (maximum uncertainty).
4. Having built a decision tree, we are using reduced error pruning to reduce the size of the tree. We select a node to collapse. For this particular node, on the left branch, there are 3 training data points with the following feature values: 5, 7, 9.6 and for the right branch, there are four training data points with the following feature values: 8.7, 9.8, 10.5, 11. What were the original responses for data points along the two branches (left & right respectively) and what is the new response after collapsing the node?
- 10.8,13.33,14.48
- 10.8,13.33,12.06
- 7.2,10,8.8
- 7.2,10,8.6
✅ Answer :-
✏️ Explanation: The average of the left values is 7.2; right is 10. After collapsing, the overall average (new response) is ~8.8.
5. Given that we can select the same feature multiple times during the recursive partitioning of the input space, is it always possible to achieve 100% accuracy on the training data (given that we allow for trees to grow to their maximum size) when building decision trees?
- Yes
- No
✅ Answer :-
✏️ Explanation: Although decision trees can overfit and achieve 100% training accuracy in most cases, it is not always guaranteed—especially if the data is noisy, inconsistent, or duplicated with different labels.
6. Suppose on performing reduced error pruning, we collapsed a node and observed an improvement in the prediction accuracy on the validation set. Which among the following statements are possible in light of the performance improvement observed?
- The collapsed node helped overcome the effect of one or more noise affected data points in the training set
- The validation set had one or more noise affected data points in the region corresponding to the collapsed node
- The validation set did not have any data points along at least one of the collapsed branches
- The validation set did not contain data points which were adversely affected by the collapsed node.
✅ Answer :- For Answer Click Here
✏️ Explanation: Pruning can help generalize better by removing overfitting due to noise. Also, if validation data doesn’t overlap with the pruned region, it reduces complexity without harming performance.
7. Considering ‘profitable’ as the binary values attribute we are trying to predict, which of the attributes would you select as the root in a decision tree with multi-way splits using the cross-entropy impurity measure?

Considering ‘profitable’ as the binary values attribute we are trying to predict, which of the attributes would you select as the root in a decision tree with multi-way splits using the cross-entropy impurity measure?
- price
- maintenance
- capacity
- airbag
✅ Answer :-
✏️ Explanation: Based on impurity measures like entropy or Gini index, “capacity” provides the best split (maximizes information gain).
8. For the same data set, suppose we decide to construct a decision tree using binary splits and the Gini index impurity measure. Which among the following feature and split point combinations would be the best to use as the root node assuming that we consider each of the input features to be unordered?
- price – {low, med}|{high}
- maintenance – {high}|{med, low}
- maintenance – {high, med}|{low}
- capacity – {2}|{4, 5}
✅ Answer :- For Answer Click Here
✏️ Explanation: This binary split minimizes the Gini index most effectively among the given options, giving the purest split.

