Introduction to Machine Learning – IITKGP Week 2 NPTEL Assignment Answers 2025
Need help with this week’s assignment? Get detailed and trusted solutions for Introduction to Machine Learning – IITKGP Week 2 NPTEL Assignment Answers. Our expert-curated answers help you solve your assignments faster while deepening your conceptual clarity.
✅ Subject: Introduction to Machine Learning – IITKGP (nptel ml Answers)
📅 Week: 2
🎯 Session: NPTEL 2025 July-October
🔗 Course Link: Click Here
🔍 Reliability: Verified and expert-reviewed answers
📌 Trusted By: 5000+ Students
For complete and in-depth solutions to all weekly assignments, check out 👉 NPTEL Introduction to Machine Learning – IITKGP Week 2 Assignment Answers
🚀 Stay ahead in your NPTEL journey with fresh, updated solutions every week!
NPTEL Introduction to Machine Learning – IITKGP Week 2 Assignment Answers 2025
1. In a binary classification problem, out of 30 data points 12 belong to class I and 18 belong to class Il. What is the entropy of the data set?
A. 0.97
B. 0
C. 1
D. 0.67
Answer : See Answers
2. Decision trees can be used for the problems where
A. the attributes are categorical.
B. the attributes are numeric valued.
C. the attributes are discrete valued.
D. In all the above cases.
Answer :
3. Which of the following is false?
A. Variance is the error of the trained classifier with respect to the best classifier in the concept class.
B. Variance depends on the training set size.
C. Variance increases with more training data.
D. Variance increases with more complicated classifiers.
Answer :
4.

Answer :





![PYQ [Week 1 to 8] NPTEL Introduction To Machine Learning – IITKGP Assignment Answers 2023](https://answergpt.in/wp-content/uploads/2024/01/NPTEL-Introduction-To-Machine-Learning-–-IITKGP-Assignment-Answers-2023.png)
5.
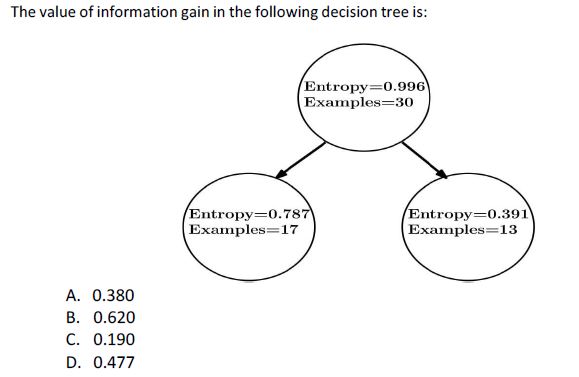
Answer :
6. What is true for Stochastic Gradient Descent?
A. In every iteration, model parameters are updated for multiple training samples
B. In every iteration, model parameters are updated for one training sample
C. In every iteration, model parameters are updated for all training samples
D. None of the above
Answer : See Answers

7. The entropy of the entire dataset is
A. 0.5
B. 1
C. 0
D. 0.1
Answer :
8. Which attribute will be the root of the decision tree?
A. Green
B. Legs
C. Height
D. Smelly
Answer :
9. In Linear Regression the output is:
A. Discrete
B. Continuous and always lies in a finite range
C. Continuous
D. May be discrete or continuous
Answer :
10. Identify whether the following statement is true or false?
“Overfitting is more likely when the set of training data is small”
A. True
B. False
Answer : See Answers
NPTEL Introduction to Machine Learning – IITKGP Week 2 Assignment Answers 2024
1. In a binary classification problem, out of 30 data points, 10 belong to Class I and 20 belong to Class II. What is the entropy of the dataset?
Options:
A. 0.97
B. 0
C. 0.91
D. 0.67
Answer: A. 0.97
Explanation:
Entropy is calculated using the formula: Entropy=−p1log2p1−p2log2p2Entropy = -p_1 \log_2 p_1 – p_2 \log_2 p_2Entropy=−p1log2p1−p2log2p2
Where p1=10/30=1/3p_1 = 10/30 = 1/3p1=10/30=1/3 and p2=20/30=2/3p_2 = 20/30 = 2/3p2=20/30=2/3 Entropy=−13log213−23log223≈0.97Entropy = -\frac{1}{3}\log_2 \frac{1}{3} – \frac{2}{3}\log_2 \frac{2}{3} \approx 0.97Entropy=−31log231−32log232≈0.97
2. Which of the following is false?
Options:
A. Bias is the true error of the best classifier in the concept class
B. Bias is high if the concept class cannot model the true data distribution well
C. High bias leads to overfitting
Answer: C. High bias leads to overfitting
Explanation:
High bias leads to underfitting, not overfitting. High variance leads to overfitting.
3. Decision trees can be used for problems where:
- The attributes are discrete valued
- The attributes are categorical
- The attributes are numeric valued
Options:
A. 1 only
B. 1 and 2 only
C. 1, 2, and 3
Answer: C. 1, 2, and 3
Explanation:
Decision trees can handle all types of features — categorical, discrete, and numeric — using appropriate splitting methods.
6. What is true for Stochastic Gradient Descent?
Options:
A. In every iteration, model parameters are updated based on multiple training samples
B. In every iteration, model parameters are updated based on one training sample
C. In every iteration, model parameters are updated based on all training samples
D. None of the above
Answer: B. In every iteration, model parameters are updated based on one training sample
Explanation:
SGD updates weights using one data point at a time, making it faster and more suitable for large datasets.
7. The entropy of the entire dataset is:
Options:
A. 0.5
B. 1
C. 0
D. 0.1
Answer: B. 1
Explanation:
Maximum entropy (uncertainty) is 1 when both classes are equally likely, i.e., 50-50 distribution.
8. Which attribute will be the root of the decision tree (if information gain is used)?
Options:
A. Green, 0.45
B. Legs, 0.4
C. Height, 0.8
D. Smelly, 0.7
Answer: C. Height, 0.8 (Assuming C is correct due to highest info gain)
Explanation:
The attribute with the highest information gain is chosen as the root. Height with 0.8 gain is the best.
9. In Linear Regression the output is:
Options:
A. Discrete
B. Continuous and always lies in a finite range
C. Continuous
D. May be discrete or continuous
Answer: C. Continuous
Explanation:
Linear Regression predicts a continuous numerical output, not limited to a specific range unless constrained.
10. **Identify whether the following statement is true or false:
“Overfitting is more likely when the set of training data is small”**
Options:
A. True
B. False
Answer: A. True
Explanation:
Small datasets can lead to models that memorize data instead of generalizing, causing overfitting.


