Introduction to Machine Learning Week 2 NPTEL Assignment Answers 2025
Need help with this week’s assignment? Get detailed and trusted solutions for Introduction to Machine Learning Week 2 NPTEL Assignment Answers. Our expert-curated answers help you solve your assignments faster while deepening your conceptual clarity.
✅ Subject: Introduction to Machine Learning (nptel ml Answers)
📅 Week: 2
🎯 Session: NPTEL 2025 July-October
🔗 Course Link: Click Here
🔍 Reliability: Verified and expert-reviewed answers
📌 Trusted By: 5000+ Students
For complete and in-depth solutions to all weekly assignments, check out 👉 NPTEL Introduction to Machine Learning Week 2 Assignment Answers
🚀 Stay ahead in your NPTEL journey with fresh, updated solutions every week!
NPTEL Introduction to Machine Learning Week 2 Assignment Answers 2024
1. State True or False:
Typically, linear regression tend to underperform compared to k-nearest neighbor algorithms when dealing with high-dimensional input spaces.
- True
- False
Answer : See Answers
2. Given the following dataset, find the uni-variate regression function that best fits the dataset.
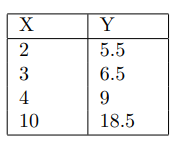
- f(x)=1×x+4
- f(x)=1×x+5
- f(x)=1.5×x+3
- f(x)=2×x+1
Answer :
3. Given a training data set of 500 instances, with each input instance having 6 dimensions and each output being a scalar value, the dimensions of the design matrix used in applying linear regression to this data is
- 500×6
- 500×7
- 500×62
- None of the above
Answer :
4. Assertion A: Binary encoding is usually preferred over One-hot encoding to represent categorical data (eg. colors, gender etc)
Reason R: Binary encoding is more memory efficient when compared to One-hot encoding
- Both A and R are true and R is the correct explanation of A
- Both A and R are true but R is not the correct explanation of A
- A is true but R is false
- A is false but R is true
Answer :


![[Week 1-12] NPTEL Introduction to Machine Learning Assignment Answers 2025](https://answergpt.in/wp-content/uploads/2025/07/Introduction-to-Machine-Learning.jpg)


![[Week 1-12] NPTEL Introduction To Machine Learning Assignment Answers 2022](https://answergpt.in/wp-content/uploads/2024/06/Introduction-To-Machine-Learning-2022.jpg)
![[Week 1-12] NPTEL Introduction to Machine Learning Assignment Answers 2024](https://answergpt.in/wp-content/uploads/2024/01/NPTEL-Introduction-to-Machine-Learning-Assignment-Answers-2024.jpeg)
5. Select the TRUE statement
- Subset selection methods are more likely to improve test error by only focussing on the most important features and by reducing variance in the fit.
- Subset selection methods are more likely to improve train error by only focussing on the most important features and by reducing variance in the fit.
- Subset selection methods are more likely to improve both test and train error by focussing on the most important features and by reducing variance in the fit.
- Subset selection methods don’t help in performance gain in any way.
Answer :
6. Rank the 3 subset selection methods in terms of computational efficiency:
- Forward stepwise selection, best subset selection, and forward stagewise regression.
- Forward stepwise selection, forward stagewise regression and best subset selection.
- Best subset selection, forward stagewise regression and forward stepwise selection.
- Best subset selection, forward stepwise selection and forward stagewise regression.
Answer :
7. Choose the TRUE statements from the following: (Multiple correct choice)
- Ridge regression since it reduces the coefficients of all variables, makes the final fit a lot more interpretable.
- Lasso regression since it doesn’t deal with a squared power is easier to optimize than ridge regression.
- Ridge regression has a more stable optimization than lasso regression.
- Lasso regression is better suited for interpretability than ridge regression.
Answer :
8. Which of the following statements are TRUE? Let xi be the i−th datapoint in a dataset of N points. Let v
represent the first principal component of the dataset. (Multiple answer questions)

Answer : See Answers
NPTEL Introduction to Machine Learning Week 2 Assignment Answers 2024
1. Which of the following statement(s) about decision boundaries and discriminant functions of classifiers is/are true?
- In a binary classification problem, all points x on the decision boundary satisfy δ1(x)=δ2(x)
- In a three-class classification problem, all points on the decision boundary satisfy δ1(x)=δ2(x)=δ3(x)
- In a three-class classification problem, all points on the decision boundary satisfy at least one of δ1(x)=δ2(x),δ2(x)=δ3(x)orδ3(x)=δ1(x).
- Let the input space be Rn. If x does not lie on the decision boundary, there exists an ϵ>0 such that all inputs y satisfying ||y−x||<ϵ belong to the same class.
Answer :- a, c, d
2. The following table gives the binary ground truth labels yi for four input points xi
(not given). We have a logistic regression model with some parameter values that computes the probability p(xi) that the label is 1. Compute the likelihood of observing the data given these model parameters.

- 0.346
- 0.230
- 0.058
- 0.086
Answer :- b
3. Which of the following statement(s) about logistic regression is/are true?
- It learns a model for the probability distribution of the data points in each class.
- The output of a linear model is transformed to the range (0, 1) by a sigmoid function.
- The parameters are learned by optimizing the mean-squared loss.
- The loss function is optimized by using an iterative numerical algorithm.
Answer :- b, d
4. Consider a modified form of logistic regression given below where k is a positive constant and β0andβ1 are parameters.

Answer :- c
5. Consider a Bayesian classifier for a 3-class classification problem. The following tables give the class-conditioned density fk(x) for three classes k=1,2,3 at some point x
in the input space.

Note that πk denotes the prior probability of class k. Which of the following statement(s) about the predicted label at x is/are true?
- If the three classes have equal priors, the prediction must be class 2
- If π3<π2andπ1<π2, the prediction may not necessarily be class 2
- If π1>2π2, the prediction could be class 1 or class 3
- If π1>π2>π3, the prediction must be class 1
Answer :- a, c
7. Which of the following statement(s) about a two-class LDA model is/are true?
- It is assumed that the class-conditioned probability density of each class is a Gaussian
- A different covariance matrix is estimated for each class
- At a given point on the decision boundary, the class-conditioned probability densities corresponding to both classes must be equal
- At a given point on the decision boundary, the class-conditioned probability densities corresponding to both classes may or may not be equal
Answer :- a, c
9. Which of the following statement(s) about LDA is/are true?
- It minimizes the between-class variance relative to the within-class variance
- It maximizes the between-class variance relative to the within-class variance
- Maximizing the Fisher information results in the same direction of the separating hyperplane as the one obtained by equating the posterior probabilities of classes
- Maximizing the Fisher information results in a different direction of the separating hyperplane from the one obtained by equating the posterior probabilities of classes
Answer :- b, d
10. Which of the following statement(s) regarding logistic regression and LDA is/are true for a binary classification problem?
- For any classification dataset, both algorithms learn the same decision boundary
- Adding a few outliers to the dataset is likely to cause a larger change in the decision boundary of LDA compared to that of logistic regression
- Adding a few outliers to the dataset is likely to cause a similar change in the decision boundaries of both classifiers
- If the within-class distributions deviate significantly from the Gaussian distribution, logistic regression is likely to perform better than LDA
Answer :- b, d


